redis之队列应用 |
您所在的位置:网站首页 › redis queue java › redis之队列应用 |
redis之队列应用
|
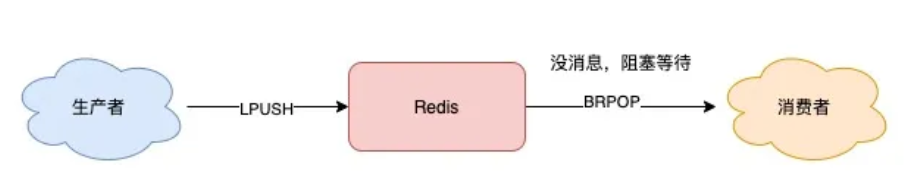
一、从最简单的开始:List 队列(LPUSH+BRPOP实现) 首先,我们先从最简单的场景开始讲起。 如果你的业务需求足够简单,想把 Redis 当作队列来使用,肯定最先想到的就是使用 List 这个数据类型。 因为 List 底层的实现就是一个「链表」,在头部和尾部操作元素,时间复杂度都是 O(1),这意味着它非常符合消息队列的模型。 如果把 List 当作队列,你可以这么来用。 生产者使用 LPUSH 发布消息: 127.0.0.1:6379> LPUSH queue msg1 (integer) 1 127.0.0.1:6379> LPUSH queue msg2 (integer) 2消费者这一侧,使用 RPOP 拉取消息: 127.0.0.1:6379> RPOP queue "msg1" 127.0.0.1:6379> RPOP queue "msg2"这个模型非常简单,也很容易理解。
但这里有个小问题,当队列中已经没有消息了,消费者在执行 RPOP 时,会返回 NULL。 127.0.0.1:6379> RPOP queue (nil) // 没消息了而我们在编写消费者逻辑时,一般是一个「死循环」,这个逻辑需要不断地从队列中拉取消息进行处理,伪代码一般会这么写: while true: msg = redis.rpop("queue") // 没有消息,继续循环 if msg == null: continue // 处理消息 handle(msg)如果此时队列为空,那消费者依旧会频繁拉取消息,这会造成「CPU 空转」,不仅浪费 CPU 资源,还会对 Redis 造成压力。 怎么解决这个问题呢? 也很简单,当队列为空时,我们可以「休眠」一会,再去尝试拉取消息。代码可以修改成这样: while true: msg = redis.rpop("queue") // 没有消息,休眠2s if msg == null: sleep(2) continue // 处理消息 handle(msg)这就解决了 CPU 空转问题。 这个问题虽然解决了,但又带来另外一个问题:当消费者在休眠等待时,有新消息来了,那消费者处理新消息就会存在「延迟」。 假设设置的休眠时间是 2s,那新消息最多存在 2s 的延迟。 要想缩短这个延迟,只能减小休眠的时间。但休眠时间越小,又有可能引发 CPU 空转问题。 鱼和熊掌不可兼得。 那如何做,既能及时处理新消息,还能避免 CPU 空转呢? Redis 是否存在这样一种机制:如果队列为空,消费者在拉取消息时就「阻塞等待」,一旦有新消息过来,就通知我的消费者立即处理新消息呢? 幸运的是,Redis 确实提供了「阻塞式」拉取消息的命令:BRPOP / BLPOP,这里的 B 指的是阻塞(Block)。
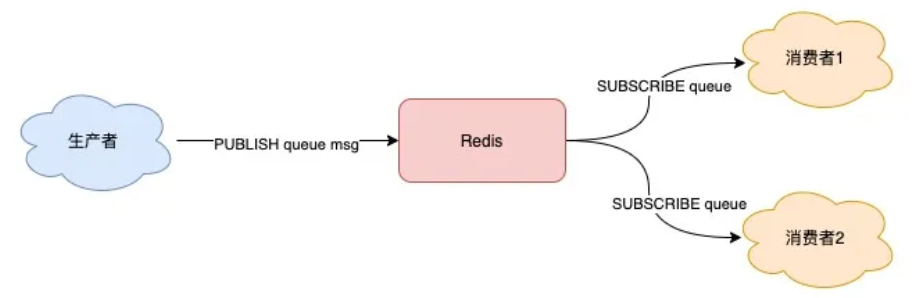
现在,你可以这样来拉取消息了: while true: // 没消息阻塞等待,0表示不设置超时时间 msg = redis.brpop("queue", 0) if msg == null: continue // 处理消息 handle(msg)使用 BRPOP 这种阻塞式方式拉取消息时,还支持传入一个「超时时间」,如果设置为 0,则表示不设置超时,直到有新消息才返回,否则会在指定的超时时间后返回 NULL。 这个方案不错,既兼顾了效率,还避免了 CPU 空转问题,一举两得。 注意:如果设置的超时时间太长,这个连接太久没有活跃过,可能会被 Redis Server 判定为无效连接,之后 Redis Server 会强制把这个客户端踢下线。所以,采用这种方案,客户端要有重连机制。 解决了消息处理不及时的问题,你可以再思考一下,这种队列模型,有什么缺点? 我们一起来分析一下: 不支持重复消费:消费者拉取消息后,这条消息就从 List 中删除了,无法被其它消费者再次消费,即不支持多个消费者消费同一批数据 消息丢失:消费者拉取到消息后,如果发生异常宕机,那这条消息就丢失了第一个问题是功能上的,使用 List 做消息队列,它仅仅支持最简单的,一组生产者对应一组消费者,不能满足多组生产者和消费者的业务场景。 第二个问题就比较棘手了,因为从 List 中 POP 一条消息出来后,这条消息就会立即从链表中删除了。也就是说,无论消费者是否处理成功,这条消息都没办法再次消费了。 这也意味着,如果消费者在处理消息时异常宕机,那这条消息就相当于丢失了。 针对这 2 个问题怎么解决呢?我们一个个来看。 二、发布/订阅模型:Pub/Sub从名字就能看出来,这个模块是 Redis 专门是针对「发布/订阅」这种队列模型设计的。 它正好可以解决前面提到的第一个问题:重复消费。 即多组生产者、消费者的场景,我们来看它是如何做的。 Redis 提供了 PUBLISH / SUBSCRIBE 命令,来完成发布、订阅的操作。
假设你想开启 2 个消费者,同时消费同一批数据,就可以按照以下方式来实现。 首先,使用 SUBSCRIBE 命令,启动 2 个消费者,并「订阅」同一个队列。 // 2个消费者 都订阅一个队列 127.0.0.1:6379> SUBSCRIBE queue Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "queue" 3) (integer) 1此时,2 个消费者都会被阻塞住,等待新消息的到来。 之后,再启动一个生产者,发布一条消息。 127.0.0.1:6379> PUBLISH queue msg1 (integer) 1这时,2 个消费者就会解除阻塞,收到生产者发来的新消息。 127.0.0.1:6379> SUBSCRIBE queue // 收到新消息 1) "message" 2) "queue" 3) "msg1"看到了么,使用 Pub/Sub 这种方案,既支持阻塞式拉取消息,还很好地满足了多组消费者,消费同一批数据的业务需求。 除此之外,Pub/Sub 还提供了「匹配订阅」模式,允许消费者根据一定规则,订阅「多个」自己感兴趣的队列。 // 订阅符合规则的队列 127.0.0.1:6379> PSUBSCRIBE queue.* Reading messages... (press Ctrl-C to quit) 1) "psubscribe" 2) "queue.*" 3) (integer) 1这里的消费者,订阅了 queue.* 相关的队列消息。 之后,生产者分别向 queue.p1 和 queue.p2 发布消息。 127.0.0.1:6379> PUBLISH queue.p1 msg1 (integer) 1 127.0.0.1:6379> PUBLISH queue.p2 msg2 (integer) 1这时再看消费者,它就可以接收到这 2 个生产者的消息了。 127.0.0.1:6379> PSUBSCRIBE queue.* Reading messages... (press Ctrl-C to quit) ... // 来自queue.p1的消息 1) "pmessage" 2) "queue.*" 3) "queue.p1" 4) "msg1" // 来自queue.p2的消息 1) "pmessage" 2) "queue.*" 3) "queue.p2" 4) "msg2"
我们可以看到,Pub/Sub 最大的优势就是,支持多组生产者、消费者处理消息。 讲完了它的优点,那它有什么缺点呢? 其实,Pub/Sub 最大问题是:丢数据。 如果发生以下场景,就有可能导致数据丢失: 消费者下线 Redis 宕机 消息堆积究竟是怎么回事? 这其实与 Pub/Sub 的实现方式有很大关系。 Pub/Sub 在实现时非常简单,它没有基于任何数据类型,也没有做任何的数据存储,它只是单纯地为生产者、消费者建立「数据转发通道」,把符合规则的数据,从一端转发到另一端。 一个完整的发布、订阅消息处理流程是这样的: 消费者订阅指定队列,Redis 就会记录一个映射关系:队列->消费者 生产者向这个队列发布消息,那 Redis 就从映射关系中找出对应的消费者,把消息转发给它
看到了么,整个过程中,没有任何的数据存储,一切都是实时转发的。 这种设计方案,就导致了上面提到的那些问题。 例如,如果一个消费者异常挂掉了,它再重新上线后,只能接收新的消息,在下线期间生产者发布的消息,因为找不到消费者,都会被丢弃掉。 如果所有消费者都下线了,那生产者发布的消息,因为找不到任何一个消费者,也会全部「丢弃」。 所以,当你在使用 Pub/Sub 时,一定要注意:消费者必须先订阅队列,生产者才能发布消息,否则消息会丢失。 这也是前面讲例子时,我们让消费者先订阅队列,之后才让生产者发布消息的原因。 另外,因为 Pub/Sub 没有基于任何数据类型实现,所以它也不具备「数据持久化」的能力。 也就是说,Pub/Sub 的相关操作,不会写入到 RDB 和 AOF 中,当 Redis 宕机重启,Pub/Sub 的数据也会全部丢失。 最后,我们来看 Pub/Sub 在处理「消息积压」时,为什么也会丢数据? 当消费者的速度,跟不上生产者时,就会导致数据积压的情况发生。 如果采用 List 当作队列,消息积压时,会导致这个链表很长,最直接的影响就是,Redis 内存会持续增长,直到消费者把所有数据都从链表中取出。 但 Pub/Sub 的处理方式却不一样,当消息积压时,有可能会导致消费失败和消息丢失! 这是怎么回事? 还是回到 Pub/Sub 的实现细节上来说。 每个消费者订阅一个队列时,Redis 都会在 Server 上给这个消费者在分配一个「缓冲区」,这个缓冲区其实就是一块内存。 当生产者发布消息时,Redis 先把消息写到对应消费者的缓冲区中。 之后,消费者不断地从缓冲区读取消息,处理消息。
但是,问题就出在这个缓冲区上。 因为这个缓冲区其实是有「上限」的(可配置),如果消费者拉取消息很慢,就会造成生产者发布到缓冲区的消息开始积压,缓冲区内存持续增长。 如果超过了缓冲区配置的上限,此时,Redis 就会「强制」把这个消费者踢下线。 这时消费者就会消费失败,也会丢失数据。 如果你有看过 Redis 的配置文件,可以看到这个缓冲区的默认配置:client-output-buffer-limit pubsub 32mb 8mb 60。 它的参数含义如下: 32mb:缓冲区一旦超过 32MB,Redis 直接强制把消费者踢下线 8mb + 60:缓冲区超过 8MB,并且持续 60 秒,Redis 也会把消费者踢下线Pub/Sub 的这一点特点,是与 List 作队列差异比较大的。 从这里你应该可以看出,List 其实是属于「拉」模型,而 Pub/Sub 其实属于「推」模型。 List 中的数据可以一直积压在内存中,消费者什么时候来「拉」都可以。 但 Pub/Sub 是把消息先「推」到消费者在 Redis Server 上的缓冲区中,然后等消费者再来取。 当生产、消费速度不匹配时,就会导致缓冲区的内存开始膨胀,Redis 为了控制缓冲区的上限,所以就有了上面讲到的,强制把消费者踢下线的机制。 好了,现在我们总结一下 Pub/Sub 的优缺点: 支持发布 / 订阅,支持多组生产者、消费者处理消息 消费者下线,数据会丢失 不支持数据持久化,Redis 宕机,数据也会丢失 消息堆积,缓冲区溢出,消费者会被强制踢下线,数据也会丢失有没有发现,除了第一个是优点之外,剩下的都是缺点。 所以,很多人看到 Pub/Sub 的特点后,觉得这个功能很「鸡肋」。 也正是以上原因,Pub/Sub 在实际的应用场景中用得并不多。 目前只有哨兵集群和 Redis 实例通信时,采用了 Pub/Sub 的方案,因为哨兵正好符合即时通讯的业务场景。 我们再来看一下,Pub/Sub 有没有解决,消息处理时异常宕机,无法再次消费的问题呢? 其实也不行,Pub/Sub 从缓冲区取走数据之后,数据就从 Redis 缓冲区删除了,消费者发生异常,自然也无法再次重新消费。 好,现在我们重新梳理一下,我们在使用消息队列时的需求。 当我们在使用一个消息队列时,希望它的功能如下: 支持阻塞等待拉取消息 支持发布 / 订阅模式 消费失败,可重新消费,消息不丢失 实例宕机,消息不丢失,数据可持久化 消息可堆积Redis 除了 List 和 Pub/Sub 之外,还有符合这些要求的数据类型吗? 其实,Redis 的作者也看到了以上这些问题,也一直在朝着这些方向努力着。 Redis 作者在开发 Redis 期间,还另外开发了一个开源项目 disque。 这个项目的定位,就是一个基于内存的分布式消息队列中间件。 但由于种种原因,这个项目一直不温不火。 终于,在 Redis 5.0 版本,作者把 disque 功能移植到了 Redis 中,并给它定义了一个新的数据类型:Stream。 下面我们就来看看,它能符合上面提到的这些要求吗? 三、基于Sorted-Set的实现 3.1、SortSet类型使用说明zset 可能是 Redis 提供的最为特色的数据结构,它也是在面试中面试官最爱问的数据结构。 一方面它是set,保证 value 的唯一性, 一方面它可以给每个 value 一个 score,代表排序权重。 它的内部实现用的是一种叫做「跳跃列表」的数据结构。 3.2、SortSet常用命令zset 中最后一个 value 被移除后,数据结构自动删除,内存被回收。 下面是zadd(添加元素)、zrange(顺序)、zrevrange(逆序)、zscore(获取score)、zrank(排名)、zrangebyscore(根据分值区间遍历)、zrem(删除)的使用示例,更多的命令说明见官方。 > zadd books 9.0 "think in java" > zadd books 8.9 "java concurrency" > zadd books 8.6 "java cookbook" > zrange books 0 -1 # 按 score 排序列出,参数区间为排名范围 1) "java cookbook" 2) "java concurrency" 3) "think in java" > zrevrange books 0 -1 # 按 score 逆序列出,参数区间为排名范围 1) "think in java" 2) "java concurrency" 3) "java cookbook" > zcard books # 相当于 count() (integer) 3 > zscore books "java concurrency" # 获取指定 value 的 score "8.9000000000000004" # 内部 score 使用 double 类型进行存储,所以存在小数点精度问题 > zrank books "java concurrency" # 排名 (integer) 1 > zrangebyscore books 0 8.91 # 根据分值区间遍历 zset 1) "java cookbook" 2) "java concurrency" > zrangebyscore books -inf 8.91 withscores # 根据分值区间 (-∞, 8.91] 遍历 zset,同时返回分值。inf 代表 infinite,无穷大的意思。 1) "java cookbook" 2) "8.5999999999999996" 3) "java concurrency" 4) "8.9000000000000004" > zrem books "java concurrency" # 删除 value (integer) 1 > zrange books 0 -1 1) "java cookbook" 2) "think in java"3.3、使用场景 3.3.1、排行榜 粉丝列表,value 值是粉丝的用户 ID,score 是关注时间 视频网站需要对用户上传的视频做排行榜,榜单维护可能是多方面:按照时间、按照播放量、按照获得的赞数等。 ------------------------------------------------------------------------------- 场景1-热门文章排序像博客、论坛等内容网站让优质内容得到足够曝光,是提高网站吸引力的重要方法。 今天我们就经常占据网站C位的 热门文章列表 这一场景来详细分析。 我们引出一个 热度 的概念,它其实是个代表文章的受欢迎程度的分数。 我们把 发布时间、点赞、评论、浏览量... 通过公式转化为热度,再根据它来排序即可 实践文章按时间倒序排序,我们可以理解了一个随时间衰减的评分,这里可以使用Unix时间。而点赞、评论、浏览量...则乘以自己的权重(常量),加上发布时间就等于文章评分 时间衰减评分首先准备文章数据:id:1文章最早发布,id:5文章最晚 [ 'id' => 1, 'title' => 'article 1', 'link' => 'http://article 1', 'user_id' => 1, 'votes' => 0, 'publish_time' => 1571190843 ], [ 'id' => 2, 'title' => 'article 2', 'link' => 'http://article 2', 'user_id' => 1, 'votes' => 0, 'publish_time' => 1571190903 ], [ 'id' => 3, 'title' => 'article 3', 'link' => 'http://article 3', 'user_id' => 1, 'votes' => 0, 'publish_time' => 1571190963 ], [ 'id' => 4, 'title' => 'article 4', 'link' => 'http://article 4', 'user_id' => 1, 'votes' => 0, 'publish_time' => 1571191023 ], [ 'id' => 5, 'title' => 'article 5', 'link' => 'http://article 5', 'user_id' => 1, 'votes' => 0, 'publish_time' => 1571191083 ]同时在Redis建立起 articles_hit_rate 文章热度 的有序列表(zset)
article 是文章id, score 为 热度评分 测试zrevrangebyscore articles_hit_rate +inf -inf 根据分数倒序取值。结果; local_redis:0>zrevrangebyscore articles_hit_rate +inf -inf 1) "5" 2) "4" 3) "3" 4) "2" 5) "1"zrevrangebyscore文档 场景2-点赞👍点赞、评论、浏览量的权重(常量),有个很好的计算方式: 发布一天内,你认为获得多少点赞👍的文章是优质文章/列表首页展示多少条数据。( 比如 100 ) 权重常量:86400 / 100 = 864 ( 一天有86400秒 ) /** * 点赞文章 * @param int $articleId 文章id * @param int $userId 用户id * @param int $voteNum 点赞数 * @return bool */ public function voteArticle( int $articleId, int $userId, int $voteNum ) { if ( $this->isVoted( $articleId, $userId ) ) return false; // 已投票,返回 $this->userVoted( $articleId, $userId ); $this->RedisUtil->hIncrBy( self::LIST_ARTICLE_PREFIXX . $articleId, 'votes', $voteNum ); // 更新文章点赞数 $this->RedisUtil->zinCrBy( self::LIST_ARTICLE_HIT_RATE, ( $voteNum * self::LIKE_HIT_RATE ), $articleId ); // 更新文章热度 return true; }至于其他维度,也可以按照点赞方法以此类推... 当然为了防止用户对同一片文章进行多次投票,还需要用Redis中无序列表set为每篇文章建立已投票用户。这个在代码里面有提现,这里就不过多讨论... 3.3.2、权重队列 / 延时队列比如:订单超时未支付,取消订单,恢复库存. 对消息队列有严格要求(不能丢)的建议还是使用kafka,专业的MQ。这些专业的消息中间件提供了很多功能特性,当然他的部署使用维护都是比较麻烦的。如果你对消息队列没那么高要求,想要轻量级的,使用Redis就没错啦。 Redis的数据结构Zset,同样可以实现延迟队列的效果,主要利用它的score属性,Redis通过score来为集合中的成员进行从小到大的排序。 
通过zadd命令向队列delayqueue中添加元素,并设置score值表示元素过期的时间;向delayqueue添加三个order1、order2、order3,分别是10秒、20秒、30秒后过期。 zadd delayqueue 3 order3消费端轮询队列delayqueue,将元素排序后取最小时间与当前时间比对,如小于当前时间代表已经过期移除key。 /** * 消费消息 */ public void pollOrderQueue() { while (true) { Set set = jedis.zrangeWithScores(DELAY_QUEUE, 0, 0); String value = ((Tuple) set.toArray()[0]).getElement(); int score = (int) ((Tuple) set.toArray()[0]).getScore(); Calendar cal = Calendar.getInstance(); int nowSecond = (int) (cal.getTimeInMillis() / 1000); if (nowSecond >= score) { jedis.zrem(DELAY_QUEUE, value); System.out.println(sdf.format(new Date()) + " removed key:" + value); } if (jedis.zcard(DELAY_QUEUE) XREAD block 1000 streams memberMessage $ (nil) (1.07s)我们使用Block模式,配合$作为ID,表示读取最新的消息,若没有消息,命令阻塞!等待过程中,其他客户端向队列追加消息,则会立即读取到。 因此,典型的队列就是 XADD 配合 XREAD Block 完成。XADD负责生成消息,XREAD负责消费消息。 4.2、消息ID说明XADD生成的1553439850328-0,就是Redis生成的消息ID,由两部分组成:时间戳-序号。时间戳是毫秒级单位,是生成消息的Redis服务器时间,它是个64位整型(int64)。序号是在这个毫秒时间点内的消息序号,它也是个64位整型。较真来说,序号可能会溢出,but真可能吗? 可以通过multi批处理,来验证序号的递增: 127.0.0.1:6379> MULTI OK 127.0.0.1:6379> XADD memberMessage * msg one QUEUED 127.0.0.1:6379> XADD memberMessage * msg two QUEUED 127.0.0.1:6379> XADD memberMessage * msg three QUEUED 127.0.0.1:6379> XADD memberMessage * msg four QUEUED 127.0.0.1:6379> XADD memberMessage * msg five QUEUED 127.0.0.1:6379> EXEC 1) "1553441006884-0" 2) "1553441006884-1" 3) "1553441006884-2" 4) "1553441006884-3" 5) "1553441006884-4"
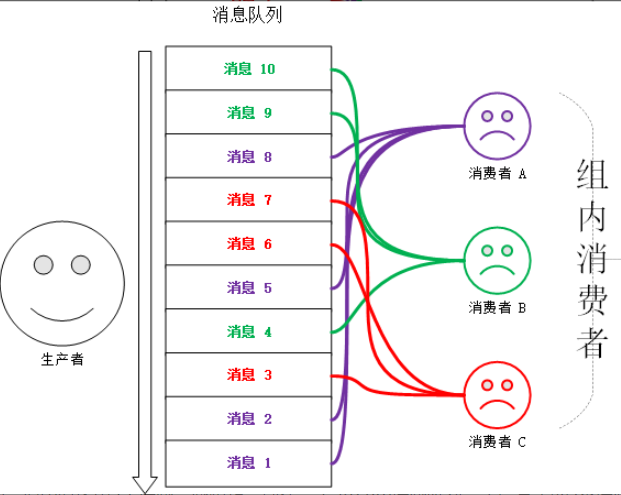
由于一个redis命令的执行很快,所以可以看到在同一时间戳内,是通过序号递增来表示消息的。 为了保证消息是有序的,因此Redis生成的ID是单调递增有序的。由于ID中包含时间戳部分,为了避免服务器时间错误而带来的问题(例如服务器时间延后了),Redis的每个Stream类型数据都维护一个latest_generated_id属性,用于记录最后一个消息的ID。若发现当前时间戳退后(小于latest_generated_id所记录的),则采用时间戳不变而序号递增的方案来作为新消息ID(这也是序号为什么使用int64的原因,保证有足够多的的序号),从而保证ID的单调递增性质。 强烈建议使用Redis的方案生成消息ID,因为这种时间戳+序号的单调递增的ID方案,几乎可以满足你全部的需求。但同时,记住ID是支持自定义的,别忘了! 4.3、消费者组模式,consumer group当多个消费者(consumer)同时消费一个消息队列时,可以重复的消费相同的消息,就是消息队列中有10条消息,三个消费者都可以消费到这10条消息。 但有时,我们需要多个消费者配合协作来消费同一个消息队列,就是消息队列中有10条消息,三个消费者分别消费其中的某些消息,比如消费者A消费消息1、2、5、8,消费者B消费消息4、9、10,而消费者C消费消息3、6、7。也就是三个消费者配合完成消息的消费,可以在消费能力不足,也就是消息处理程序效率不高时,使用该模式。该模式就是消费者组模式。如下图所示:
消费者组模式的支持主要由两个命令实现: XGROUP,用于管理消费者组,提供创建组,销毁组,更新组起始消息ID等操作 XREADGROUP,分组消费消息操作进行演示,演示时使用5个消息,思路是:创建一个Stream消息队列,生产者生成5条消息。在消息队列上创建一个消费组,组内三个消费者进行消息消费: # 生产者生成10条消息 127.0.0.1:6379> MULTI 127.0.0.1:6379> XADD mq * msg 1 # 生成一个消息:msg 1 127.0.0.1:6379> XADD mq * msg 2 127.0.0.1:6379> XADD mq * msg 3 127.0.0.1:6379> XADD mq * msg 4 127.0.0.1:6379> XADD mq * msg 5 127.0.0.1:6379> EXEC 1) "1553585533795-0" 2) "1553585533795-1" 3) "1553585533795-2" 4) "1553585533795-3" 5) "1553585533795-4" # 创建消费组 mqGroup 127.0.0.1:6379> XGROUP CREATE mq mqGroup 0 # 为消息队列 mq 创建消费组 mgGroup OK # 消费者A,消费第1条 127.0.0.1:6379> XREADGROUP group mqGroup consumerA count 1 streams mq > #消费组内消费者A,从消息队列mq中读取一个消息 1) 1) "mq" 2) 1) 1) "1553585533795-0" 2) 1) "msg" 2) "1" # 消费者A,消费第2条 127.0.0.1:6379> XREADGROUP GROUP mqGroup consumerA COUNT 1 STREAMS mq > 1) 1) "mq" 2) 1) 1) "1553585533795-1" 2) 1) "msg" 2) "2" # 消费者B,消费第3条 127.0.0.1:6379> XREADGROUP GROUP mqGroup consumerB COUNT 1 STREAMS mq > 1) 1) "mq" 2) 1) 1) "1553585533795-2" 2) 1) "msg" 2) "3" # 消费者A,消费第4条 127.0.0.1:6379> XREADGROUP GROUP mqGroup consumerA count 1 STREAMS mq > 1) 1) "mq" 2) 1) 1) "1553585533795-3" 2) 1) "msg" 2) "4" # 消费者C,消费第5条 127.0.0.1:6379> XREADGROUP GROUP mqGroup consumerC COUNT 1 STREAMS mq > 1) 1) "mq" 2) 1) 1) "1553585533795-4" 2) 1) "msg" 2) "5" 上面的例子中,三个在同一组 mpGroup 消费者A、B、C在消费消息时(消费者在消费时指定即可,不用预先创建),有着互斥原则,消费方案为,A->1, A->2, B->3, A->4, C->5。语法说明为: XGROUP CREATE mq mqGroup 0,用于在消息队列mq上创建消费组 mpGroup,最后一个参数0,表示该组从第一条消息开始消费。(意义与XREAD的0一致)。除了支持CREATE外,还支持SETID设置起始ID,DESTROY销毁组,DELCONSUMER删除组内消费者等操作。 XREADGROUP GROUP mqGroup consumerA COUNT 1 STREAMS mq >,用于组mqGroup内消费者consumerA在队列mq中消费,参数>表示未被组内消费的起始消息,参数count 1表示获取一条。语法与XREAD基本一致,不过是增加了组的概念。 可以进行组内消费的基本原理是,STREAM类型会为每个组记录一个最后处理(交付)的消息ID(last_delivered_id),这样在组内消费时,就可以从这个值后面开始读取,保证不重复消费。 以上就是消费组的基础操作。除此之外,消费组消费时,还有一个必须要考虑的问题,就是若某个消费者,消费了某条消息,但是并没有处理成功时(例如消费者进程宕机),这条消息可能会丢失,因为组内其他消费者不能再次消费到该消息了。下面继续讨论解决方案。 4.4、Pending 等待列表为了解决组内消息读取但处理期间消费者崩溃带来的消息丢失问题,STREAM 设计了 Pending 列表,用于记录读取但并未处理完毕的消息。命令XPENDIING 用来获消费组或消费内消费者的未处理完毕的消息。演示如下: 127.0.0.1:6379> XPENDING mq mqGroup # mpGroup的Pending情况 1) (integer) 5 # 5个已读取但未处理的消息 2) "1553585533795-0" # 起始ID 3) "1553585533795-4" # 结束ID 4) 1) 1) "consumerA" # 消费者A有3个 2) "3" 2) 1) "consumerB" # 消费者B有1个 2) "1" 3) 1) "consumerC" # 消费者C有1个 2) "1" 127.0.0.1:6379> XPENDING mq mqGroup - + 10 # 使用 start end count 选项可以获取详细信息 1) 1) "1553585533795-0" # 消息ID 2) "consumerA" # 消费者 3) (integer) 1654355 # 从读取到现在经历了1654355ms,IDLE 4) (integer) 5 # 消息被读取了5次,delivery counter 2) 1) "1553585533795-1" 2) "consumerA" 3) (integer) 1654355 4) (integer) 4 # 共5个,余下3个省略 ... 127.0.0.1:6379> XPENDING mq mqGroup - + 10 consumerA # 在加上消费者参数,获取具体某个消费者的Pending列表 1) 1) "1553585533795-0" 2) "consumerA" 3) (integer) 1641083 4) (integer) 5 # 共3个,余下2个省略 ...每个Pending的消息有4个属性: 消息ID 所属消费者 IDLE,已读取时长 delivery counter,消息被读取次数上面的结果我们可以看到,我们之前读取的消息,都被记录在Pending列表中,说明全部读到的消息都没有处理,仅仅是读取了。那如何表示消费者处理完毕了消息呢?使用命令 XACK 完成告知消息处理完成,演示如下: 127.0.0.1:6379> XACK mq mqGroup 1553585533795-0 # 通知消息处理结束,用消息ID标识 (integer) 1 127.0.0.1:6379> XPENDING mq mqGroup # 再次查看Pending列表 1) (integer) 4 # 已读取但未处理的消息已经变为4个 2) "1553585533795-1" 3) "1553585533795-4" 4) 1) 1) "consumerA" # 消费者A,还有2个消息处理 2) "2" 2) 1) "consumerB" 2) "1" 3) 1) "consumerC" 2) "1" 127.0.0.1:6379>有了这样一个Pending机制,就意味着在某个消费者读取消息但未处理后,消息是不会丢失的。等待消费者再次上线后,可以读取该Pending列表,就可以继续处理该消息了,保证消息的有序和不丢失。 此时还有一个问题,就是若某个消费者宕机之后,没有办法再上线了,那么就需要将该消费者Pending的消息,转义给其他的消费者处理,就是消息转移。请继续。 4.5、 消息转移消息转移的操作时将某个消息转移到自己的Pending列表中。使用语法XCLAIM来实现,需要设置组、转移的目标消费者和消息ID,同时需要提供IDLE(已被读取时长),只有超过这个时长,才能被转移。演示如下: # 当前属于消费者A的消息1553585533795-1,已经15907,787ms未处理了 127.0.0.1:6379> XPENDING mq mqGroup - + 10 1) 1) "1553585533795-1" 2) "consumerA" 3) (integer) 15907787 4) (integer) 4 # 转移超过3600s的消息1553585533795-1到消费者B的Pending列表 127.0.0.1:6379> XCLAIM mq mqGroup consumerB 3600000 1553585533795-1 1) 1) "1553585533795-1" 2) 1) "msg" 2) "2" # 消息1553585533795-1已经转移到消费者B的Pending中。 127.0.0.1:6379> XPENDING mq mqGroup - + 10 1) 1) "1553585533795-1" 2) "consumerB" 3) (integer) 84404 # 注意IDLE,被重置了 4) (integer) 5 # 注意,读取次数也累加了1次以上代码,完成了一次消息转移。转移除了要指定ID外,还需要指定IDLE,保证是长时间未处理的才被转移。被转移的消息的IDLE会被重置,用以保证不会被重复转移,以为可能会出现将过期的消息同时转移给多个消费者的并发操作,设置了IDLE,则可以避免后面的转移不会成功,因为IDLE不满足条件。例如下面的连续两条转移,第二条不会成功。 127.0.0.1:6379> XCLAIM mq mqGroup consumerB 3600000 1553585533795-1 127.0.0.1:6379> XCLAIM mq mqGroup consumerC 3600000 1553585533795-1这就是消息转移。至此我们使用了一个Pending消息的ID,所属消费者和IDLE的属性,还有一个属性就是消息被读取次数,delivery counter,该属性的作用由于统计消息被读取的次数,包括被转移也算。这个属性主要用在判定是否为错误数据上。请继续看: 4.6 坏消息问题,Dead Letter,死信问题正如上面所说,如果某个消息,不能被消费者处理,也就是不能被XACK,这是要长时间处于Pending列表中,即使被反复的转移给各个消费者也是如此。此时该消息的delivery counter就会累加(上一节的例子可以看到),当累加到某个我们预设的临界值时,我们就认为是坏消息(也叫死信,DeadLetter,无法投递的消息),由于有了判定条件,我们将坏消息处理掉即可,删除即可。删除一个消息,使用XDEL语法,演示如下: # 删除队列中的消息 127.0.0.1:6379> XDEL mq 1553585533795-1 (integer) 1 # 查看队列中再无此消息 127.0.0.1:6379> XRANGE mq - + 1) 1) "1553585533795-0" 2) 1) "msg" 2) "1" 2) 1) "1553585533795-2" 2) 1) "msg" 2) "3"注意本例中,并没有删除Pending中的消息因此你查看Pending,消息还会在。可以执行XACK标识其处理完毕! 4.7 信息监控,XINFOStream提供了XINFO来实现对服务器信息的监控,可以查询: 查看队列信息 127.0.0.1:6379> Xinfo stream mq 1) "length" 2) (integer) 7 3) "radix-tree-keys" 4) (integer) 1 5) "radix-tree-nodes" 6) (integer) 2 7) "groups" 8) (integer) 1 9) "last-generated-id" 10) "1553585533795-9" 11) "first-entry" 12) 1) "1553585533795-3" 2) 1) "msg" 2) "4" 13) "last-entry" 14) 1) "1553585533795-9" 2) 1) "msg" 2) "10"消费组信息 127.0.0.1:6379> Xinfo groups mq 1) 1) "name" 2) "mqGroup" 3) "consumers" 4) (integer) 3 5) "pending" 6) (integer) 3 7) "last-delivered-id" 8) "1553585533795-4"消费者组成员信息 127.0.0.1:6379> XINFO CONSUMERS mq mqGroup 1) 1) "name" 2) "consumerA" 3) "pending" 4) (integer) 1 5) "idle" 6) (integer) 18949894 2) 1) "name" 2) "consumerB" 3) "pending" 4) (integer) 1 5) "idle" 6) (integer) 3092719 3) 1) "name" 2) "consumerC" 3) "pending" 4) (integer) 1 5) "idle" 6) (integer) 23683256至此,消息队列的操作说明大体结束! 4.8 命令一览|命令|说明| |:---|:---| |XACK|结束Pending| |XADD|生成消息| |XCLAIM|消息转移| |XDEL|删除消息| |XGROUP|消费组管理| |XINFO|得到消费组信息| |XLEN|消息队列长度| |XPENDING|Pending列表| |XRANGE|获取消息队列中消息| |XREAD|消费消息| |XREADGROUP|分组消费消息| |XREVRANGE|逆序获取消息队列中消息| |XTRIM|消息队列容量| 4.9 Stream数据结构,RadixTree,基数树Stream 是基于 RadixTree 数据结构实现的。另立话题讨论。基数树,http://www.hellokang.net/algorithm/radix-tree.html 五、stream的队列示例生产者发布 2 条消息: // *表示让Redis自动生成消息ID 127.0.0.1:6379> XADD queue * name zhangsan "1618469123380-0" 127.0.0.1:6379> XADD queue * name lisi "1618469127777-0"使用 XADD 命令发布消息,其中的「*」表示让 Redis 自动生成唯一的消息 ID。 这个消息 ID 的格式是「时间戳-自增序号」。 消费者拉取消息: // 从开头读取5条消息,0-0表示从开头读取 127.0.0.1:6379> XREAD COUNT 5 STREAMS queue 0-0 1) 1) "queue" 2) 1) 1) "1618469123380-0" 2) 1) "name" 2) "zhangsan" 2) 1) "1618469127777-0" 2) 1) "name" 2) "lisi"如果想继续拉取消息,需要传入上一条消息的 ID: 127.0.0.1:6379> XREAD COUNT 5 STREAMS queue 1618469127777-0 (nil)没有消息,Redis 会返回 NULL。
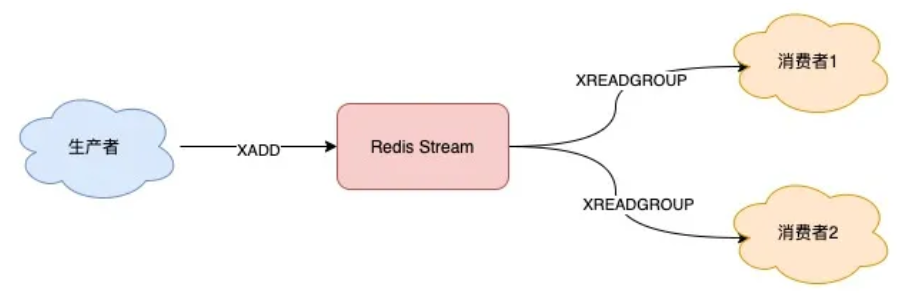
以上就是 Stream 最简单的生产、消费。 这里不再重点介绍 Stream 命令的各种参数,我在例子中演示时,凡是大写的单词都是「固定」参数,凡是小写的单词,都是可以自己定义的,例如队列名、消息长度等等,下面的例子规则也是一样,为了方便你理解,这里有必要提醒一下。 下面我们来看,针对前面提到的消息队列要求,Stream 都是如何解决的? 1) Stream 是否支持「阻塞式」拉取消息? 可以的,在读取消息时,只需要增加 BLOCK 参数即可。 // BLOCK 0 表示阻塞等待,不设置超时时间127.0.0.1:6379> XREAD COUNT 5 BLOCK 0 STREAMS queue 1618469127777-0这时,消费者就会阻塞等待,直到生产者发布新的消息才会返回。 2) Stream 是否支持发布 / 订阅模式? 也没问题,Stream 通过以下命令完成发布订阅: XGROUP:创建消费者组 XREADGROUP:在指定消费组下,开启消费者拉取消息下面我们来看具体如何做? 首先,生产者依旧发布 2 条消息: 127.0.0.1:6379> XADD queue * name zhangsan"1618470740565-0"127.0.0.1:6379> XADD queue * name lisi"1618470743793-0"之后,我们想要开启 2 组消费者处理同一批数据,就需要创建 2 个消费者组: // 创建消费者组1,0-0表示从头拉取消息127.0.0.1:6379> XGROUP CREATE queue group1 0-0OK// 创建消费者组2,0-0表示从头拉取消息127.0.0.1:6379> XGROUP CREATE queue group2 0-0OK消费者组创建好之后,我们可以给每个「消费者组」下面挂一个「消费者」,让它们分别处理同一批数据。 第一个消费组开始消费: // group1的consumer开始消费,>表示拉取最新数据127.0.0.1:6379> XREADGROUP GROUP group1 consumer COUNT 5 STREAMS queue >1) 1) "queue" 2) 1) 1) "1618470740565-0" 2) 1) "name" 2) "zhangsan" 2) 1) "1618470743793-0" 2) 1) "name" 2) "lisi"同样地,第二个消费组开始消费: // group2的consumer开始消费,>表示拉取最新数据127.0.0.1:6379> XREADGROUP GROUP group2 consumer COUNT 5 STREAMS queue >1) 1) "queue" 2) 1) 1) "1618470740565-0" 2) 1) "name" 2) "zhangsan" 2) 1) "1618470743793-0" 2) 1) "name" 2) "lisi"我们可以看到,这 2 组消费者,都可以获取同一批数据进行处理了。 这样一来,就达到了多组消费者「订阅」消费的目的。
3) 消息处理时异常,Stream 能否保证消息不丢失,重新消费? 除了上面拉取消息时用到了消息 ID,这里为了保证重新消费,也要用到这个消息 ID。 当一组消费者处理完消息后,需要执行 XACK 命令告知 Redis,这时 Redis 就会把这条消息标记为「处理完成」。 // group1下的 1618472043089-0 消息已处理完成127.0.0.1:6379> XACK queue group1 1618472043089-0
如果消费者异常宕机,肯定不会发送 XACK,那么 Redis 就会依旧保留这条消息。 待这组消费者重新上线后,Redis 就会把之前没有处理成功的数据,重新发给这个消费者。这样一来,即使消费者异常,也不会丢失数据了。 // 消费者重新上线,0-0表示重新拉取未ACK的消息127.0.0.1:6379> XREADGROUP GROUP group1 consumer1 COUNT 5 STREAMS queue 0-0// 之前没消费成功的数据,依旧可以重新消费1) 1) "queue" 2) 1) 1) "1618472043089-0" 2) 1) "name" 2) "zhangsan" 2) 1) "1618472045158-0" 2) 1) "name" 2) "lisi"4) Stream 数据会写入到 RDB 和 AOF 做持久化吗? Stream 是新增加的数据类型,它与其它数据类型一样,每个写操作,也都会写入到 RDB 和 AOF 中。 我们只需要配置好持久化策略,这样的话,就算 Redis 宕机重启,Stream 中的数据也可以从 RDB 或 AOF 中恢复回来。 5) 消息堆积时,Stream 是怎么处理的? 其实,当消息队列发生消息堆积时,一般只有 2 个解决方案: 生产者限流:避免消费者处理不及时,导致持续积压 丢弃消息:中间件丢弃旧消息,只保留固定长度的新消息而 Redis 在实现 Stream 时,采用了第 2 个方案。 在发布消息时,你可以指定队列的最大长度,防止队列积压导致内存爆炸。 // 队列长度最大10000127.0.0.1:6379> XADD queue MAXLEN 10000 * name zhangsan"1618473015018-0"当队列长度超过上限后,旧消息会被删除,只保留固定长度的新消息。 这么来看,Stream 在消息积压时,如果指定了最大长度,还是有可能丢失消息的。 除了以上介绍到的命令,Stream 还支持查看消息长度(XLEN)、查看消费者状态(XINFO)等命令,使用也比较简单,你可以查询官方文档了解一下,这里就不过多介绍了。 好了,通过以上介绍,我们可以看到,Redis 的 Stream 几乎覆盖到了消息队列的各种场景,是不是觉得很完美? 既然它的功能这么强大,这是不是意味着,Redis 真的可以作为专业的消息队列中间件来使用呢? 但是还「差一点」,就算 Redis 能做到以上这些,也只是「趋近于」专业的消息队列。 原因在于 Redis 本身的一些问题,如果把其定位成消息队列,还是有些欠缺的。 到这里,就不得不把 Redis 与专业的队列中间件做对比了。 下面我们就来看一下,Redis 在作队列时,到底还有哪些欠缺? 六、与专业的消息队列对比其实,一个专业的消息队列,必须要做到两大块: 消息不丢 消息可堆积前面我们讨论的重点,很大篇幅围绕的是第一点展开的。 这里我们换个角度,从一个消息队列的「使用模型」来分析一下,怎么做,才能保证数据不丢? 使用一个消息队列,其实就分为三大块:生产者、队列中间件、消费者。
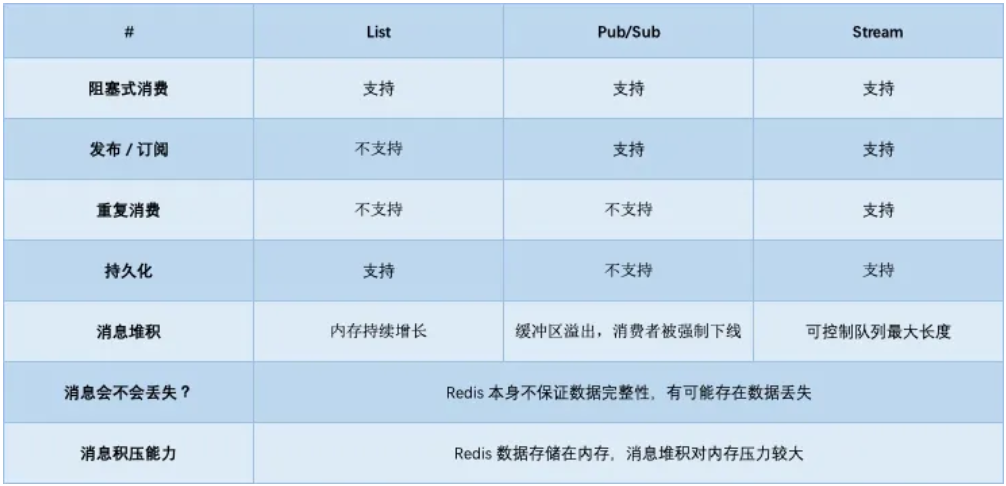
消息是否会发生丢失,其重点也就在于以下 3 个环节: 生产者会不会丢消息? 消费者会不会丢消息? 队列中间件会不会丢消息?1) 生产者会不会丢消息? 当生产者在发布消息时,可能发生以下异常情况: 消息没发出去:网络故障或其它问题导致发布失败,中间件直接返回失败 不确定是否发布成功:网络问题导致发布超时,可能数据已发送成功,但读取响应结果超时了如果是情况 1,消息根本没发出去,那么重新发一次就好了。 如果是情况 2,生产者没办法知道消息到底有没有发成功?所以,为了避免消息丢失,它也只能继续重试,直到发布成功为止。 生产者一般会设定一个最大重试次数,超过上限依旧失败,需要记录日志报警处理。 也就是说,生产者为了避免消息丢失,只能采用失败重试的方式来处理。 但发现没有?这也意味着消息可能会重复发送。 是的,在使用消息队列时,要保证消息不丢,宁可重发,也不能丢弃。 那消费者这边,就需要多做一些逻辑了。 对于敏感业务,当消费者收到重复数据数据时,要设计幂等逻辑,保证业务的正确性。 从这个角度来看,生产者会不会丢消息,取决于生产者对于异常情况的处理是否合理。 所以,无论是 Redis 还是专业的队列中间件,生产者在这一点上都是可以保证消息不丢的。 2) 消费者会不会丢消息? 这种情况就是我们前面提到的,消费者拿到消息后,还没处理完成,就异常宕机了,那消费者还能否重新消费失败的消息? 要解决这个问题,消费者在处理完消息后,必须「告知」队列中间件,队列中间件才会把标记已处理,否则仍旧把这些数据发给消费者。 这种方案需要消费者和中间件互相配合,才能保证消费者这一侧的消息不丢。 无论是 Redis 的 Stream,还是专业的队列中间件,例如 RabbitMQ、Kafka,其实都是这么做的。 所以,从这个角度来看,Redis 也是合格的。 3) 队列中间件会不会丢消息? 前面 2 个问题都比较好处理,只要客户端和服务端配合好,就能保证生产端、消费端都不丢消息。 但是,如果队列中间件本身就不可靠呢? 毕竟生产者和消费这都依赖它,如果它不可靠,那么生产者和消费者无论怎么做,都无法保证数据不丢。 在这个方面,Redis 其实没有达到要求。 Redis 在以下 2 个场景下,都会导致数据丢失。 AOF 持久化配置为每秒写盘,但这个写盘过程是异步的,Redis 宕机时会存在数据丢失的可能 主从复制也是异步的,主从切换时,也存在丢失数据的可能(从库还未同步完成主库发来的数据,就被提成主库)基于以上原因我们可以看到,Redis 本身的无法保证严格的数据完整性。 所以,如果把 Redis 当做消息队列,在这方面是有可能导致数据丢失的。 再来看那些专业的消息队列中间件是如何解决这个问题的? 像 RabbitMQ 或 Kafka 这类专业的队列中间件,在使用时,一般是部署一个集群,生产者在发布消息时,队列中间件通常会写「多个节点」,以此保证消息的完整性。这样一来,即便其中一个节点挂了,也能保证集群的数据不丢失。 也正因为如此,RabbitMQ、Kafka在设计时也更复杂。毕竟,它们是专门针对队列场景设计的。 但 Redis 的定位则不同,它的定位更多是当作缓存来用,它们两者在这个方面肯定是存在差异的。 最后,我们来看消息积压怎么办? 4) 消息积压怎么办? 因为 Redis 的数据都存储在内存中,这就意味着一旦发生消息积压,则会导致 Redis 的内存持续增长,如果超过机器内存上限,就会面临被 OOM 的风险。 所以,Redis 的 Stream 提供了可以指定队列最大长度的功能,就是为了避免这种情况发生。 但 Kafka、RabbitMQ 这类消息队列就不一样了,它们的数据都会存储在磁盘上,磁盘的成本要比内存小得多,当消息积压时,无非就是多占用一些磁盘空间,相比于内存,在面对积压时也会更加「坦然」。 综上,我们可以看到,把 Redis 当作队列来使用时,始终面临的 2 个问题: Redis 本身可能会丢数据 面对消息积压,Redis 内存资源紧张到这里,Redis 是否可以用作队列,我想这个答案你应该会比较清晰了。 如果你的业务场景足够简单,对于数据丢失不敏感,而且消息积压概率比较小的情况下,把 Redis 当作队列是完全可以的。 而且,Redis 相比于 Kafka、RabbitMQ,部署和运维也更加轻量。 如果你的业务场景对于数据丢失非常敏感,而且写入量非常大,消息积压时会占用很多的机器资源,那么我建议你使用专业的消息队列中间件。 七、总结好了,总结一下。这篇文章我们从「Redis 能否用作队列」这个角度出发,介绍了 List、Pub/Sub、Stream 在做队列的使用方式,以及它们各自的优劣。 之后又把 Redis 和专业的消息队列中间件做对比,发现 Redis 的不足之处。 最后,我们得出 Redis 做队列的合适场景。 这里我也列了一个表格,总结了它们各自的优缺点。
最后,我想和你再聊一聊关于「技术方案选型」的问题。 你应该也看到了,这篇文章虽然始于 Redis,但并不止于 Redis。 我们在分析 Redis 细节时,一直在提出问题,然后寻找更好的解决方案,在文章最后,又聊到一个专业的消息队列应该怎么做。 其实,我们在讨论技术选型时,就是一个关于如何取舍的问题。 而这里我想传达给你的信息是,在面对技术选型时,不要不经过思考就觉得哪个方案好,哪个方案不好。 你需要根据具体场景具体分析,这里我把这个分析过程分为 2 个层面: 业务功能角度 技术资源角度这篇文章所讲到的内容,都是以业务功能角度出发做决策的。 但这里的第二点,从技术资源角度出发,其实也很重要。 技术资源的角度是说,你所处的公司环境、技术资源能否匹配这些技术方案。 这个怎么解释呢? 简单来讲,就是你所在的公司、团队,是否有匹配的资源能 hold 住这些技术方案。 我们都知道 Kafka、RabbitMQ 是非常专业的消息中间件,但它们的部署和运维,相比于 Redis 来说,也会更复杂一些。 如果你在一个大公司,公司本身就有优秀的运维团队,那么使用这些中间件肯定没问题,因为有足够优秀的人能 hold 住这些中间件,公司也会投入人力和时间在这个方向上。 但如果你是在一个初创公司,业务正处在快速发展期,暂时没有能 hold 住这些中间件的团队和人,如果贸然使用这些组件,当发生故障时,排查问题也会变得很困难,甚至会阻碍业务的发展。 而这种情形下,如果公司的技术人员对于 Redis 都很熟,综合评估来看,Redis 也基本可以满足业务 90% 的需求,那当下选择 Redis 未必不是一个好的决策。 所以,做技术选型不只是技术问题,还与人、团队、管理、组织结构有关。 也正是因为这些原因,当你在和别人讨论技术选型问题时,你会发现每个公司的做法都不相同。 毕竟每个公司所处的环境和文化不一样,做出的决策当然就会各有差异。 如果你不了解这其中的逻辑,那在做技术选型时,只会趋于表面现象,无法深入到问题根源。 而一旦你理解了这个逻辑,那么你在看待这个问题时,不仅对于技术会有更加深刻认识,对技术资源和人的把握,也会更加清晰。 希望你以后在做技术选型时,能够把这些因素也考虑在内,这对你的技术成长之路也是非常有帮助的。 转: https://mp.weixin.qq.com/s/jYldDKkxypj53NaogQj40Q https://www.imooc.com/article/298523 https://zhuanlan.zhihu.com/p/60501638 https://juejin.cn/post/6844903968326287368 https://juejin.im/post/5eb4bb615188256d7674a7fb |








【本文地址】